Часть третья. Шаг за шагом, или как мы строили свой поиск.
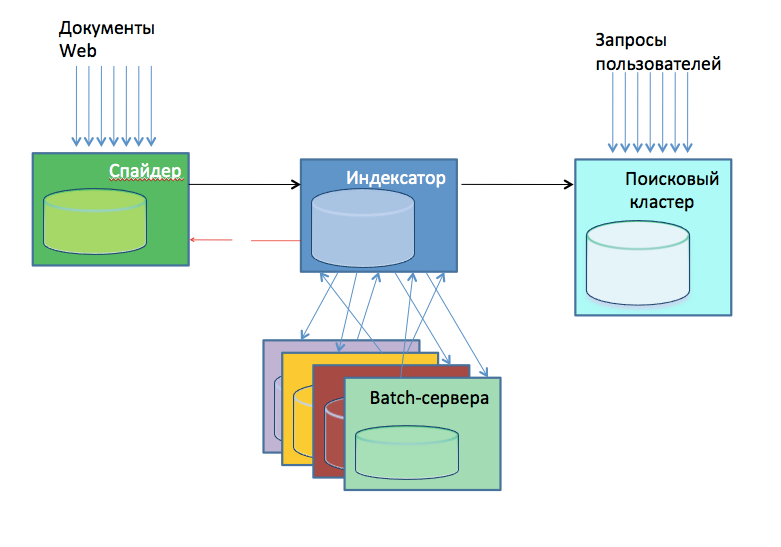
В прошлом посте мы рассмотрели примеры архитектуры поисковиков. Везде ключевую роль играет база данных, над которой удобно производить некоторые операции, исследовать и анализировать содержащиеся в ней документы.
До весны 2012 года у нас вместо такой базы существовали две базы данных разного уровня — со стороны спайдера, который имел свою собственную базу URL-ов, и со стороны индексатора. Это было крайне неудобно: допустим, если пользователь жаловался, что его сайт не индексируется, то для того, чтобы найти причину, при старой архитектуре пришлось бы анализировать массу данных. На это требовалось день-два, иногда даже неделя.
Задачи, которые обрабатывали данные, такие как антиспам или ссылочный граф, вынуждены были работать отдельно, создавая еще большую путаницу. Мы понимали, что нужно что-то менять.
Готовое решение или собственная реализация? После обдумывания чужих архитектур стало понятно, что необходима платформа для распределённого выполнения задач. Мы остановились на Hadoop — системе, которая позволяет распараллелить вычисления на большом кластере машин. У этого решения достаточно примеров успешного использования в крупнейших компаниях, таких, как Facebook и Yahoo! — а значит, мы могли быть уверены, что Hadoop справляется с большими объёмами данных.
В качестве альтернативы мы рассматривали несколько вариантов. Одним из них была система Sector/Sphere. К сожалению, тесты в других отделах нашей компании показывали, что система на тот момент была довольно сырой, и мы не могли уверенно на нее положиться.
Ещё один вариант — написать решение самостоятельно. Некоторые компании идут по такому пути: например, известно, что в Яндексе есть своя собственная реализация и MapReduce, и распределённой файловой системы. Мы проанализировали плюсы и минусы собственной реализации по сравнению с Hadoop. Использование самописного решения было бы оправдано, если бы мы нашли примеры того, что Hadoop работает медленнее или требует больше ресурсов, чем реализация, сделанная самостоятельно.
Единственное, что нас пугало — то, что Hadoop был написан на Java. Программистов на С и C++ Java часто отталкивает довольно вальяжным отношением к ресурсам: среди них распространено мнение, что программа, написанная на Java, будет работать в 2, в 3, а то и в 10 раз медленнее, чем программа, написанная на языке С++. Это оказалось мифом: после того, как мы пересели на Hadoop, многие из наших программистов познакомились с Java, и выяснялось, что часто написать программу на Java можно быстрее, чем на С++, и работать она будет примерно с той же скоростью, что и ее аналог. Конечно же, в использовании Java достаточно нюансов, неприятных для программистов С++ (например, тот же самый сборщик мусора) — но это уже следующий этап применения.
Тестирование Hadoop показало, что Java нас не страшит, а по результатам личных бесед с разработчиками систем распределённых вычислений выяснилось, что скорость Hadoop не слишком отличается от реализаций, сделанных самостоятельно: что хорошо отлаженная реализация на языке C++ всего в полтора раза быстрее, чем Hadoop. Из этого стало понятно, что делать собственное решение нет смысла — мы потратим значительно больше сил для того, чтобы его реализовать; поэтому Hadoop у нас прижился.
Конечно, программисты, которые пересаживались на вычислительный кластер из шестидесяти серверов, испытывали эйфорию. Всё то, что раньше программист делал долго и мучительно, то, что выполнялось на серверах по несколько недель, теперь программировалось за день и выполнялось в течение 15 – 10 минут. Конечно, когда практически все программисты пересели на Hadoop, задачи, запущенные внутри кластера, выполнялись уже не так быстро. Но всё же иметь общую платформу было очень удобно. Стало понятно, что в итоге мы будем использовать Hadoop.
Клоны BigTable: HBase, Hypertable, Cassandra Далее мы начали думать над тем, как реализовать базу данных с информацией об обкачанных URL-ах. На этом этапе возникало множество вопросов. Например: у нас есть список URL-ов и контент URL-ов — стоит ли держать их в одном файле или лучше разбить на два? Логично разбить: ведь контент, в отличие от URL-ов, нужен не всегда. А если мы хотим что-то быстро дописать к этому файлу — неужели мы будем для этого проходить по нему, чтобы скопировать его в новое место с новыми изменениями? Напрашивается решение — создать рядом ещё один небольшой файл, в который мы допишем новые изменения, и проходить по двум файлам параллельно.
В итоге, размышляя подобным образом, рано или поздно ловишь себя на мысли «Это же BigTable», так что мы решили исследовать известные Open Source-аналоги.
Свободно распространяемых клонов BigTable было три: первый — HBase, построенный в рамках того же коммьюнити, которое сделало Hadoop, второй — HyperTable, и третий — опенсорсное решение Cassandra, скопированное с решения Dynamo (которое, в свою очередь, было создано в Amazon по мотивам BigTable).
Нас интересовало удобство использования в наших условиях, скорость и, конечно, стабильность работы. О соответствии последнему критерию можно судить по тому, сколько компаний используют ту или иную таблицу. HyperTable отпал практически сразу, поскольку нас не устроила его стабильность: на тот момент из крупных сервисов его использовал только китайский поисковик Baidu. Установить его на стенд получилось с огромным трудом, что практически гарантировало огромное количество головной боли при использовании (сейчас, по отзывам, он стал значительно более удобным).
Оставалось два варианта — Cassandra и HBase. Cassandra обеспечивала большую скорость, но и давала более высокий риск потери данных. У HBase, наоборот, была ниже скорость записи, зато выше надежность. Кроме того, HBase тесно интегрировался с Hadoop. Это и стало для нас решающим аргументом в его пользу.
Мы начали тестирование HBase с небольшого кластера на 16 машин. Первые тесты были успешными — всё работало стабильно и с приемлемой скоростью. Скоро число серверов в кластере увеличилось до 32, а потом и до 50.
Тогда же мы решили, что не станем сразу строить полноценный поисковик, который будет работать рядом с основным. Когда две версии «тяжёлого» веб-сервиса — раннюю и позднюю — развивают параллельно, второй, как правило, не удается догнать первую. В первой версии постоянно появляются новые фичи, которые во второй просто не успевают реализовывать; в результате новая версия поиска имела бы риск так и не стать релизной.
Поэтому мы решили начинать с малого: взять задачу, которая неоптимально решена в нашем основном поисковике, и решить ее с помощью новых технологий и ориентируясь на новую архитектуру. В качестве такой задачи мы выбрали быстрый и регулярный обход интересных для нас документов. Фактически, примерно за 3 месяца мы запустили рядом с существующим спайдером его специализированную версию, но сразу же включённую в общий рабочий цикл поисковика. Еще 3 месяца потребовалось на его стабилизацию, тонкую настройку и создание патчей для HBase, после чего мы выключили старый спайдер и полностью перешли на новую систему.
По предварительным оценкам весь процесс должен был занять около полутора-двух месяцев. Однако мы недооценили сроки — выяснилось, что HBase был далёк от совершенства и стабильность его работы в тех задачах, для которых мы его использовали, оставляла желать лучшего. Мы несколько раз порывались начать разрабатывать собственное решение, но каждый раз анализировали ситуацию и приходили к выводу, что заточить под наши потребности HBase будет всё-таки проще.
Наш опыт саппорта В процессе «приручения» Hadoop и HBase мы поняли, что нам необходима помощь более опытных людей — поэтому мы приобрели коммерческую поддержку компании Cloudera.
Опыт взаимодействия с саппортом был двояким. Конечно, тесное знакомство с Cloudera помогло нам ответить на большое количество вопросов, но некоторые из полученных ответов нас не устроили. Например, через какое-то время мы поняли, что Cloudera тоже не знает, как можно настроить HBase так, чтобы он работал в наших условиях — просто потому, что у них кластеров с таким объёмом данных нет в поддержке. Компании, работающие с подобными объёмами — те же Facebook или Yahoo! — решили эту проблему, приняв в штат людей, которые разрабатывали HBase. Таким образом, в Cloudera не могли нам порекомендовать ничего конкретного, и во многом мы остались там же, где и были. С этого момента мы поняли, что можем рассчитывать только на собственные силы.
Проблемы и как мы их решали
Все проблемы, которые у нас возникли с HBase и Hadoop, подробно были описаны на Форуме Технологий Mail.Ru Group в докладе, который делал Максим Лапань (см. здесь: techforum.mail.ru/video/). Я же обрисую их вкратце.
Первое: объём нашей таблицы постоянно рос. Изначально мы рассчитывали, что в таблице будет 5–10 миллиардов документов. Однако быстро выяснилось, что это число должно быть гораздо больше, и в базу необходимо вместить 20–40 миллиардов URL-ов. Это означало, что мы ошиблись в оценке объёма кластера: в результате нам пришлось расширить его сначала до 100, а потом до 170 серверов. В итоге мы стали обладателями одного из самых больших кластеров, на котором развёрнут HBase; во всяком случае, в России нам кластеры большего размера неизвестны.
Вторая проблема возникла с паттерном использования HBase. Каждый день мы выкачивали примерно 500 миллионов, а то и миллиард документов. На тот момент у нас было 5–10 миллиардов документов с контентом; таким образом, ежедневно обновлялось около 10-20% объёма базы. При таком режиме работы HBase, установленный из коробки, всё время занят тем, что старается перепаковать эту базу, на что тратится ресурсы сети и дисков. В результате задачи выполняются крайне медленно. Решить эту проблему настройкой HBase было невозможно, так что нам пришлось его патчить. В итоге мы выложили несколько патчей разной сложности, которые помогли сократить время на служебные операции с HBase.
Третья проблема заключалась в том, что ежедневные проходы выполнения задач над большой базой происходили очень медленно, поскольку неосторожный фильтр при сканировании данных приводил к тому, что поднимались все значения из таблицы, включая контент, который там хранился; это приводило к тому, что задача вместо запланированных 2–3 часов выполнялась сутками. Учитывая, что в то время наш кластер часто падал, задача могла просто не дойти до завершения. Решение также было реализовано в виде патча, позволяющего ускорить проходы по таблице за счёт «быстрых сканов». Мы его выложили для обсуждения в issue tracker Apache https://issues.apache.org/jira/browse/HBASE-5416, где собралось большинство активных разработчиков HBase, но так как патч затрагивает много корневых элементов HBase, он до сих пор не был интегрирован в общий код. Этот патч стал самым крупным, и именно с окончанием его разработки наш кластер наконец заработал.
Четвертая большая проблема, которую мы пока не побороли – это несбалансированность регионов HBase.
Тут стоит подробней рассмотреть подход к хранению web-страниц в HBase. Классическим примером использования HBase является хранение в нем содержимого документов с URL-ом в виде ключа. Домены в URL-е записываются в обратном порядке, чтобы не только страницы сайта, но и поддомены одного домена располагались рядом, например вот так:

Такой подход соблазнял своей логичностью, и мы поступили так же. Проблема же состоит в том, что набор URL-ов расширяется со временем, и велика вероятность того, что мы найдем много страниц с одного домена. Соответствующий регион в HBase будет заметно «толще» среднего.
Для преодоления этой проблемы в HBase существует механизм деления регионов. Но обратный механизм — слияния — работает нестабильно. А постоянное увеличение количества регионов в целях балансировки приводит к большим накладным расходам на их обслуживание.
И после написания множества задач для Hadoop мы повторно задумались – а что нам дает близость документов в таблице? Это удобно для пары задач, но в целом порождает больше проблем. И сейчас мы движемся в сторону внедрения хэширования для URL-ов. Таким образом, документы будут распределены равномерно; равномерным станет и время выполнения mapper-ов, а значит, ускорятся все задачи работающие с HBase.
Пока мы работали над решениями, всё больше компонентов нашего Поиска переезжало в Hadoop. Сейчас все компоненты, кроме индексации, работают в Hadoop и в HBase.
Наверное, мы в итоге сделали то, чего хотели с самого начала: у нас появилась платформа для распределённых вычислений, анализа данных. Нельзя сказать, что мы ею довольны полностью — просто потому, что в процессе прохождения пути приходит понимание того, что ещё хотелось бы получить от платформы. Но сейчас со времени появления нового URL-а и до того момента, когда он появляется в индексе, проходит от 2 до 5 дней. В старой версии поисковика это могло происходить от двух недель и больше. Следующая наша цель — сократить время до минут. Архитектура новой версии поисковика скорее всего будет принципиально отличаться от существующей.
MapReduce и спайдер Парадигма MapReduce и отлаженная технология Hadoop дают возможность легко масштабировать кластер. Увеличиваем количество серверов в 1.5 раза – задачи начинают работают [почти] в 1.5 раза быстрее. Однако не все задачи «ложатся» на парадигму MapReduce, а некоторые просто не испытывают от нее никаких улучшений. Это верно, например, для web-спайдера: занимать слот под выкачку сайта невыгодно – всегда будут медленные хостинги, из-за которых драгоценный слот придется держать дольше, чем это необходимо.
Кроме того, подход «делаем все в рамках MapReduce» приводит к неэффективному использованию ресурсов, ведь для выкачки страниц необходима быстрая сеть, а, скажем, для разбора содержимого страниц – быстрый CPU.
Именно такой процесс разделения произошел в нашем краулере. Прежде это была монолитная задача которая производила:
•DNS-resolving + выкачку страниц (требует сеть)
•Разбор содержимого (CPU)
•Проверку и импорт ссылок (CPU + много ОЗУ)
•Хранение содержимого и бэкап (диски)
•Перестройку очереди выкачки (CPU + много ОЗУ)
Масштабировать такой спайдер было крайне сложно: добавление новых машин означало переразбиение базы, что занимало несколько недель. А провести эксперимент с модификацией, скажем, схемы определения языка документа было просто невозможно: такой тест занимал месяцы.
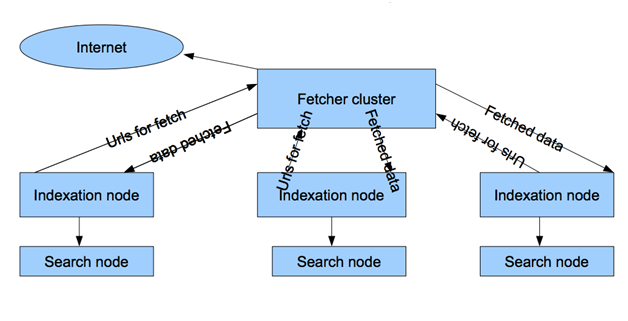
Переход на Hadoop избавил нас от проблем хранения бэкапов и дал простую масштабируемость для задач, требовательных к CPU и ОЗУ. Сам же краулер стал выполнять лишь функцию выкачки и был переименован в fetcher:

Сейчас, когда мы имеем всю «бизнес-логику» в MapReduce, а сами документы в HBase, внедрение нового определения языка стало задачей одного дня.
Мы рассмотрели переход на единую платформу вычислений Hadoop. Внедрение Hadoop для нашего проекта стало, пожалуй, самым революционным архитектурным решением. Переход на Hadoop и MapReduce продолжается для компонент, производящих вычисления «в оффлайне». Архитектура же «онлайновой» части, обрабатывающей пользовательские запросы, а также процесс создания поискового индекса, будут рассмотрены далее.
Индексация данных Индексация данных у нас происходит вне MapReduce, но также распределена по отдельным машинам и относительно легко масштабируется.
Индексация работает с т.н. микробазами: все множество web’а разделено на 2048 кусков, сгруппированных по сайтам. Индексация данных инкрементальная: новые данные индексируются поверх имеющейся базы, а затем данные склеиваются. На каждой машине- «индексаторе» существует несколько очередей, распределенных по дискам. Каждая очередь обрабатывает несколько микробаз.
Типовая машина-индексатор выглядит примерно так:

Узкими местами для индексаторов является CPU и диски, именно поэтому индексаторы комплектуются дисками по количеству ядер; таково же и количество очередей обработки.
Данные для индексации, т.е. документы и их атрибуты, берутся из HDFS. Это частичные дампы все той же таблицы HBase, о которой говорилось ранее. В результате индексации обновленные микробазы складывается в HDFS, и впоследствии копируется на поисковые сервера.
Несмотря на то, что сами индексаторы работают вне парадигмы MapReduce, Hadoop помогает также и в этой задаче: центральным хранилищем микробаз и главным бэкапом является HDFS. Кроме того, тяжелые части индексаторов также переводятся в Hadoop, дабы индесаторы больше занимались своей прямой задачей – составлением бинарного индекса данных.
Поисковый демон
Задачи веб-поиска – это нахождение документов, соответствующих запросу, их ранжирование и формирование информативной выдачи, главным образом — сниппетов. Именно эти задачи решает отдельный поисковый бэкенд. Выдача же результата для SERP-а формируется объединением ответов бэкендов. Эту функцию выполняет компонент, который обычно называется мета-поиском (о нем — в следующем разделе).
Основное техническое требование к бэкенду – это время ответа. Бэкендам приходится работать с огромным количеством данных и большим потоком запросов. Спонтанная задержка, скажем, из-за блокирования на диске должна быть исключением, но не регулярным правилом.
Поисковая база традиционно состоит из обратного и прямого индексов, а также вспомогательных файлов: числовых свойств документов, позапросной информации и т.п. Обратный индекс используется для поиска документов и ранжирования. Прямой индекс используется для построения сниппетов. Существует множество подходов к тому, что из этого всегда хранить в памяти, что кэшировать, а что – зачитывать с диска.
Мы руководствовались простым правилом: чем прозрачней будет наша система, тем более предсказуемо она будет работать. Это не касается, скажем, такой части, как зачитывание сжатых индексных блоков. Разумеется, чем быстрее работает эта фаза, тем быстрее работает весь поиск. И эта часть у поисковиков традиционно отшлифована и оптимизирована под современные процессоры. Но сложная схема кэширования блоков индекса у нас отсутствует.
Вместо этого наиболее востребованные части мы просто блокируем в ОЗУ (Unix, mlock(2)). Сюда же попадают и части со средней востребованностью, но произвольным характером доступа к ним, например, числовые свойства документов. А вот прямой индекс мы храним на диске, надеясь на кэш ОС. Заметим, что прямой индекс востребован существенно реже обратного, ведь независимо от увеличения количества поисковых машин пользователям по-прежнему необходимо лишь несколько результатов в выдаче.
Что же касается организации процессов-демонов, то они работают в многопроцессной схеме master-workers. Учитывая разделение на микробазы (mdb), обозначенное в предыдущем разделе, схема бэкенда выглядит так:

Метапоиск сперва запрашивает у всех бэкендов небольшое количество результатов, производит их слияние, а далее получает сниппеты тех документов, которые попадут в выдачу.
Подобно остальным поисковикам, мы производим склеивание результатов «на лету». Так, например, мы удаляем дублирующиеся описания из выдачи. Соответственно, мы вынуждены делать дополнительные запросы к бэкендам, а для ускорения ответа – запрашивать с небольшим упреждением.
Метапоиск Традиционная схема поиска включает в себя множество бэкендов и компонент, производящий объединение частичных результатов на основе весов (релевантности):
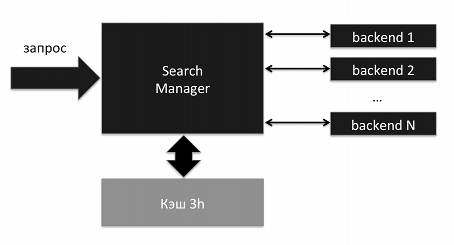
Аналогичная схема у нас распространялась и на т.н. вертикали — поиск по картинкам и видео. Но в виде подмесов к основной выдаче вертикали работали так, чтобы уложится в классическую схему: у картинок и роликов были свои веса, которые подстраивались под документы из web.
Гарантировать, что картинка появится на первом месте, достаточно просто. А что делать с весами, если мы хотим поставить ее на 3-ю позицию? Добавлять такую логику в search-manager не хотелось: все же его задача – это банальное объединение результатов. Поэтому мы сделали дополнительный узел, назначение которого — высокоуровневая работа с результатами и встраивание подмесов. В итоге схема нашего “middle-end”-а мутировала в следующую:

Такая схема обеспечила и независимость разработки smanager-meta и прежнего smanager-а. Благодаря этому встраивать подмесы стало гораздо проще, и сейчас мы подмешиваем свыше 20 разнообразных вертикалей.
Это изменение также позволило нам выделить «быстрые базы» в отдельный блок и разделить кэширование результатов. Результаты из «быстрых баз» мы кэшируем на 15 минут, а результаты «большого web-а» — на сутки.
В компонент smanager-meta также перешла фаза предобработки запроса: применение синонимов, переформулировка запроса и составление дерева поиска. Эта достаточно емкая часть поисковика наверняка будет описана в последующих постах.
Послесловие
Мы рассмотрели архитектуру Поиска Mail.Ru и то, как она изменилась со времен, когда мы были поисковиком GoGo, обслуживающим всего 10 запросов в секунду. Часть решений диктовалась именно на порядки возросшей нагрузкой. Остальное – желанием привнести гибкость и ускорить темпы разработки.
Отдельно хочется сказать про выбор средств для работы системы. Многие существующие компоненты не готовы к использованию в среде, где требуется высокая производительность при большом объеме данных. Именно поэтому большинство компонент пишутся или дорабатываются под нашу инфраструктуру. В это число входят и наши доработки, касающиеся Apache HBase. Все это дает возможность более плотно использовать имеющееся оборудование. Так, даже после того, как мы значительно нарастили парк серверов, стоимость обработки одного запроса у нас осталась относительно невысокой.
Несомненно, архитектура находится в тесной связи с внешними требованиями. Меняющиеся на порядки объемы данных или количество запросов вынуждают изменять и схемы их обработки. Вполне вероятно, что представленные подходы также претерпят изменения через несколько лет. Но есть ощущение, что мы сделали существенный шаг для того, чтобы больше сконцентрироваться на качестве поиска. На том, как нас будет воспринимать наш пользователь.
* И как в всегда в комментариях тоже есть кое что интересное помимо справедливой критики.