
-- Алексей Мыльников написал 1 октября 2010 17:04
Если в версии 6.4.5.5 в пакете написать два запроса (можно не в пакете, а по-отдельности в "Золотом ключике" выполнить эти запросы):
запрос1 --noturl.txt
запрос2 --Мои документы\нет.txt
предварительно в корневой папке СайтСпутник(а) создать файл: noturl.txt, содержащий:
sitesputnik.ru
ab.vlink.ru
youtube.com
livejournal.com
freesoft.ru
shareware.su
Интернет-проект
СМИ
метапоиск в интернете
средство для поиска в интернете
а в папке "Мои документы", вложенной в корневую папку, создать файл: нет.txt, содержащий:
ci-razvedka.ru
sitesputnik.ru/Help
То выдача SiteSputnik(a) для:
"запрос1" не будет содержать сниппетов, в html-тексте которых содержатся абсолютно точные копии строк из файла noturl.txt,
"запрос2" не будет содержать сниппетов, в html-тексте которых содержатся абсолютно точные копии строк из файла Мои документы\нет.txt
-- petryashov написал 1 октября 2010 19:08
2 Alexei Mylnikov
Ага, понятно. А можно сделать так, чтобы файлы noturl.txt и нет.txt заполнялись при помощи интерфейса, встроенного в саму программу SiteSputnik? А то некоторых юзеров будет напрягать необходимость создавать какие-то файлы и их куда-то сохранять...
-- Алексей Мыльников написал 2 октября 2010 18:37
petryashov написал:
Ага, понятно. А можно сделать так, чтобы файлы noturl.txt и нет.txt заполнялись при помощи интерфейса, встроенного в саму программу SiteSputnik? А то некоторых юзеров будет напрягать необходимость создавать какие-то файлы и их куда-то сохранять...
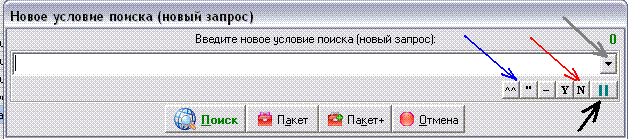 (http://sitesputnik.ru/Help/Pic/BlackList.GIF)
(http://sitesputnik.ru/Help/Pic/BlackList.GIF)Красная стрелка на картинке указывает на кнопку "N", по которой осуществляется переход к работе с "Черным списком".
Нажав ее, затем можно выбрать готовый список, отредактировать его в блокноте или создать новый список.
В перспективе можно будет повесить более "комфортабельную" отдельную картиночку на кнопку "N" под работу с черными списками, а не стандартный диалог как в настоящей версии.
Правила:
для каждого простого запроса допускается один черный список;
в пакете каждому запросу можно прописать один свой (персональный) черный список.
Это доступно в версии 6.4.5.6 от 02.10.10г.
Подкачаться можно из главного меню "? | Проверить наличие обновлений".
-- petryashov написал 4 октября 2010 16:55
Ага, работает, но хитро: один раз ссылку на "забаненный" сайт все же выдает
-- Алексей Мыльников написал 4 октября 2010 19:24
petryashov написал:
Ага, работает, но хитро: один раз ссылку на "забаненный" сайт все же выдает
Такого быть не должно: смотрите внимательнее на имя сайта в выдаче и на то, что указано в чёрном списке.
-- petryashov написал 7 октября 2010 9:31
Вот один скриншот:
-- petryashov написал 7 октября 2010 9:32
А вот второй скриншот:
-- Алексей Мыльников написал 7 октября 2010 9:38
А не в виде скриншота, а файлы "Объединение" и "Черный список" пришлите мне на почту.
-- Алексей Мыльников написал 11 октября 2010 12:44
Файлов не дождался. Тогда посмотрите:
1) Вы поставили два минуса перед "Черным списком" --Джи И Индастри.txt;
2) Нет ли пробела после www.ge-industry.ru в "Черном списке".
У меня на запросе: "Джи И Индастри" --Джи И Индастри.txt все работает правильно.
-- petryashov написал 12 октября 2010 12:46
2Alexei Mylnikov
Спасибо, посмотрю
-- tungus1973 написал 3 ноября 2010 16:26
К посту № 12 в этой теме.
Можно ли аналогично сделать Вайтлист сайтов?

запрос1 ++url.txt
В файле "url.txt" перечисляем все возможные конструкции слов, которые непременно должны присутствовать в сниппетах.
-- Алексей Мыльников написал 3 ноября 2010 16:38
tungus1973 написал:
К посту № 12 в этой теме.
Можно ли аналогично сделать Вайтлист сайтов?
запрос1 ++url.txt
В файле "url.txt" перечисляем все возможные конструкции слов, которые непременно должны присутствовать в сниппетах.
Можно.
-- Алексей Мыльников написал 5 ноября 2010 15:27
В версии 6.4.7 от 05.11.10 можно применять ++url.txt.
Файл url.txt содержит список точных (с учетом регистра) слов и фраз, хотя бы одно из которых должно присутствовать в сниппете. Например, если содержание этого файла таково:
sitesputnik.ru
ab.vlink.ru
freesoft.ru
ci-razvedka.ru
razvedka-internet.ru
info-war.ru
nejdanov.ru
informnn.ru
marketinginform.ru
forum.razved.info
а сам запрос: sitesputnik | "сайтспутник" ++url.txt
то выдача будет содержить страницы c упоминанием программы СайтСпутник и хотя бы одного из 10 перечисленных выше сайтов. Если требуется конструкция --url2.txt, то она должна следовать после конструкции ++url.txt
-- CI-KP написал 5 ноября 2010 16:51
tungus1973 написал:
К посту № 12 в этой теме.
Можно ли аналогично сделать Вайтлист сайтов?
запрос1 ++url.txt
В файле "url.txt" перечисляем все возможные конструкции слов, которые непременно должны присутствовать в сниппетах.
А можно попросить кино или скриншоты? А то я пока так и не понял, что куда вписывать для этого надо.
-- tungus1973 написал 5 ноября 2010 16:51
Особенно понравилось, что теперь можно комбинировать ++txt и --txt.
Класс!

-- Алексей Мыльников написал 5 ноября 2010 18:12
CI-KP написал:
А можно попросить кино или скриншоты? А то я пока так и не понял, что куда вписывать для этого надо.
 (http://sitesputnik.ru/Help/Pic/BlackWhite.GIF)
(http://sitesputnik.ru/Help/Pic/BlackWhite.GIF)1. Вводим запрос. Он обведен зеленым прямоугольноком.
2. Нажимает на кнопку "Y" и выбираем белый список. Если он не готов, то можно создать и заполнить его прямо на катринке стандартного диалога.
3. Нажимает на кнопку "N" и выбираем черный список. Если он не готов, то можно создать и заполнить его прямо на катринке стандартного диалога.
Замечания.
1. Подобное можно делать и для отдельных запросов в пакете.
2. Стандартный диалог в будущем можно будет заменить на специальный диалог, чтобы упростить работу пользователя.
-- CI-KP написал 5 ноября 2010 18:25
Алексей, спасибо! А файл этот со списком куда надо положить?
-- Алексей Мыльников написал 5 ноября 2010 18:34
CI-KP написал:
А файл этот со списком куда надо положить?
Оба файла: белый список и черный список, - удобнее положить в корневую папку СайтСпутник(а). Можно создать вложенную папку, например, с именем My и складывать файлы в нее.
-- CI-KP написал 5 ноября 2010 18:47
Спасибо!
-- Доктор ТуамОсес написал 2 сентября 2013 20:50
Вы здесь:http://forum.razved.info/index.php?t=1170&p=14290#pp14290 самое главное не сказали.
Что создаваемый файл слов исключений должен быть в кодировке ASCII.
А ведь все современные редакторы сохраняют файлы в юникоде.
Из-за этого я почти месяц мучился и не мог понять: почему у меня не работает "черный список"

-- Доктор ТуамОсес написал 2 сентября 2013 20:59
================================================================================
И ещё вопрос к разработчику: не планируется ли расширить возможности файлов слов исключений возможностью добавлять REGEX-ы? Ну или хотя бы фразы?
Этого очень не хватает
-- Игорь Нежданов написал 3 сентября 2013 10:41
Дима, Олег - так понимаю вы эту тему освоили ("черные" и "белые" списки сайтов).
Подскажите - этот список глобально действует или локально (в рамках одного Проекта). И если локально - то как создавать списки под каждый проект?
-- Алексей Мыльников написал 3 сентября 2013 12:36
Доктор ТуамОсес написал:
И ещё вопрос к разработчику: не планируется ли расширить возможности файлов слов исключений возможностью добавлять REGEX-ы? Ну или хотя бы фразы?
"Городить большой огород" специально над сниппетами считаю, что не рационально. Если очень надо, то есть более мощная возможность работы с ними, но в SiteSputnik News, а именно:
1. Для источников в "Настройка поиска" (но не в Main сценарии) прописываете "Да" в столбце "Сниппет-Новость" (сниппет есть новость), то есть, на рубрикацию отправляете не скачанный контент ссылки, а контент сниппета.
2. Создаёте новостной пакет (проект) и в нем прописываете Рубрику или несколько Рубрик, в которых можно задать Правила попадания в Рубрику (http://sitesputnik.ru/Help/SSRubriki.htm), которые значительно мощнее, чем REGEX-ы и простые фразы.
Если в пакете для всех источников прописано, что сниппет есть новость, то он отработает быстро, так как скачивания ссылок проводиться не будет, а сами новости будут очень маленькими и их рубрикация пройдет очень быстро.
-- Алексей Мыльников написал 3 сентября 2013 13:00
Игорь Нежданов написал:
Подскажите - этот список глобально действует или локально (в рамках одного Проекта). И если локально - то как создавать списки под каждый проект?
Список действует локально, причем привязан не к проекту, а явно прописывается в строке запроса, там где это нужно.
-- Игорь Нежданов написал 3 сентября 2013 13:05
Алексей Мыльников написал:
Список действует локально...
Это очень хорошо. Потопал пробовать. Спасибо!
-- Доктор ТуамОсес написал 5 сентября 2013 21:18
Для: Игорь Нежданов
Список (в смысле файл чёрного списка) как я понял действует только в текущем запросе.
P.S. А что такое "проект"& Ящик что ли?
-- Алексей Мыльников написал 6 сентября 2013 17:22
Доктор ТуамОсес написал:
А что такое "проект"& Ящик что ли?
Проект - может быть простым поисковым или новостным (с поиском, скачиванием и рубрикацией новых материалов или обновлений).
Типы новостных Проектов перечислены в "Инструкторе".
Ящик - это база данных (Пользователь видит две взаимосвязанные таблицы), в которой сохраняется история работы с Проектом.
В принцине, в одном Ящике можно вести несколько Проектов, но в реальной работе каждый Проект удобнее вести в своем Ящике.
-- Доктор ТуамОсес написал 6 сентября 2013 19:22
Алексей Мыльников написал:
Проект - может быть простым поисковым или новостным
Всё-равно не очень понятно, что Вы подразумеваете под словом "проект" в своей программе.
Дайте формальное и математически строгое определение
-- Доктор ТуамОсес написал 8 сентября 2013 15:52
Алексей Мыльников написал:
запрос2 --Мои документы\нет.txt
Т.е. SS автоматом находит папку "Мои документы"?

Как? Сканируя более чем полтора миллиона файлов на моем харде?
А если я, к примеру, хочу чтобы у меня файлы черного и белого списков лежали на диске E:, то как в этом случае будет выглядеть запрос?
Так: папа --E:\Папка для списков SiteSputnik\Чёрный список.TXT
ДА?
-- Алексей Мыльников написал 8 сентября 2013 17:10
Если не указан полный путь, то путь к файлу ищется относительно главной папки программы.
То есть, для Ваших случаев:
- папка "Мои документы" должна быть вложена в папку FileForFiles,
- папка E:\Папка для списков SiteSputnik, должна быть на диске E:\
-- Доктор ТуамОсес написал 8 сентября 2013 18:52
Для: Алексей Мыльников
А можно ли в черных и белых списках вводить целые фразы? (Т.е. чтобы в исключаемой цепочке символов были пробелы)
Допустим я не хочу чтобы в сниппете была фраза "Алексей Толстой"
Что я должен написать в черном списке?
Два слова? "Алексей" и "Толстой"?
Но тогда отфильтруются и сниппеты где "Алексей" без "Толстой" и "Толстой" без "Алексей"
P.S. Админу: Почему у меня не работают HTML-теги?

-- Алексей Мыльников написал 8 сентября 2013 19:13
Доктор ТуамОсес написал:
А можно ли в черных и белых списках вводить целые фразы?
Вы совсем недавно в этой теме в #32 задавали этот вопрос. Ответ был дан в #34.
-- CI-KP написал 8 сентября 2013 20:11
Доктор ТуамОсес написал:
P.S. Админу: Почему у меня не работают HTML-теги?
Потому что у Вас мало сообщений. А спамеры любят ставить теги.
P.S. А будете орать - забаним на денек, чтобы остыли :)
-- Доктор ТуамОсес написал 8 сентября 2013 21:57
Алексей Мыльников написал:
"Городить большой огород" специально над сниппетами считаю, что не рационально. Если очень надо, то есть более мощная возможность работы с ними, но в SiteSputnik News
Т.е. предлагаете установить другую программу?
Т.е. под каждую задачу я должен ставить новую программу?
-- Алексей Мыльников написал 8 сентября 2013 22:13
Доктор ТуамОсес написал:
Т.е. предлагаете установить другую программу?
Т.е. под каждую задачу я должен ставить новую программу?
Нет, нужен более продвинутый вариант программы SiteSputnik, один для всех подобных задач.
-- Доктор ТуамОсес написал 10 сентября 2013 21:31
Для: Алексей Мыльников
"Хлопотно это"(с)
Домохозяйки не поймут.
Гораздо проще и быстрей просто составить список "фраз" которых не должно быть в сниппетах.
А для юзверей "покруче" можно добавить возможность добавлять не просто фразы, а паттерны (regex-ы).
И всё. Для 99,87% юзверей этих возможностей "за глаза" хватит.
Просто даже если программа самая суперская, но если уровень её сложности начинает превышать некоторый порог, то количество её юзверей скачком падает практически до нуля.
Вам оно надо?
-- Алексей Мыльников написал 11 сентября 2013 13:46
Для Доктор ТуамОсес.
То есть фразы сначала были нужны, а теперь уже нет? Вы как-то разберитесь сами с собой и перечитывайте то, что писали ранее.
По существу,
нет смысла специально развивать для сниппетов сложные операции вида: фразы, логичеcкое "И", "Не", "ИЛИ" между ними, расстояние между словами, точные фразы, ...
Причина следующая: сниппет, грубо говоря, составляет одну десятую или меньшую часть контента ссылки. Это приведёт к потере точности поиска на этих операциях до "неузнаваемости".
Лучше тщательнее сформируйте сами запросы, входящие в пакет запросов. Тогда будет толк.
Черные и белые списки предназначены для действий над адресом ссылки, который есть практически в любом сниппете, или для отсева заведомо ненужной информации по списку слов. Именно это и реализовано в СайтСпутнике.
Более сложные операции имеет смысл применять на полном контенте ссылки, а не на сниппетах.
-- tungus1973 написал 11 сентября 2013 14:38
Дополню слова Алексея Борисовича.
В СайтСпутнике версии "Ньюс" реализован мощный механизм рубрикации, который позволяет собирать именно то, что нужно, отсеивая лишнее. Рубрикатор эффективно корректирует ошибки поисковиков. Даже работая с поисковиком, обладающим примитивными возможностями языка запросов, Вы сможете выбирать из него именно то, что соответствует вашим потребностям.
Алексей Борисович правильно Вам указал, что если Вы будете опираться только на возможности поисковиков и работать только со сниппетами, то упустите массу ценной информации.
-- petryashov написал 11 сентября 2013 15:12
2 Доктор ТуамОсес
Демо- версия для серьезной работы непригодна. Она для этого и не предназначена. Минимальная конфигурация, которая позволяет автоматизировать большинство вопросов информационного обеспечения бизнеса - это SiteSputnik + News.
-- Доктор ТуамОсес написал 18 сентября 2013 11:44
Алексей Мыльников написал:
То есть фразы сначала были нужны, а теперь уже нет? Вы как-то разберитесь сами с собой
Нужны, Алексей Мыльников, нужны.
Поэтому очень Вас прошу добавить их. Пожалуйста. Я же не регулярки прошу добавить (хотя это было бы вообще айс
 ), а просто чтобы и пробельные символы участвовали в сравнении, чтобы в блэк и вайт листы можно было заносить целые фразы. Это же буквально пару-тройку строчек в исходнике программы поправить. Плиз.
), а просто чтобы и пробельные символы участвовали в сравнении, чтобы в блэк и вайт листы можно было заносить целые фразы. Это же буквально пару-тройку строчек в исходнике программы поправить. Плиз.Просто иначе ценность/кайф использования черных/белых списков практически нивелируется до нуля.

Просто бывает так, что на сотне доменов находится одна и та же инфа (рерайтеры, копирайтеры (или как там их?) не зря же едят свой хлеб). Соответственно, в выдаче будет присутствовать сотня сниппетов с разными URL-ами но одним и тем же текстом.
Поэтому придётся в ручную набивать в блэк листе все эти сто доменов.
А введя, к примеру
Лев Толстойможно было бы одним выстрелом убить сразу сто зайцев. Тем более что может мне не надо фильтровать весь домен, мне нужно отфильтровать определенные веб-странички домена, содержащие не нужную мне инфу. Поэтому оптимальней бы было заносить в блэк лист не URL домена, а фразы, которых не должно быть в выдаче
-- Алексей Мыльников написал 18 сентября 2013 23:28
Доктор ТуамОсес написал:
ТолстойА их что два было (шутка, не моя)?
А если серьёзно, то в топиках #34 и #48 я Вам подробно ответил.
Ещё раз коротко: во-первых, уже есть возможность рубрикации сниппетов, что мощнее фраз и regex, во-вторых, не считаю рациональным тратить силы на совершенствование правил для белых и черных списков, потому что сложные правила на сниппете, составляющем 0.1-0.01 часть контента ссылки сработают, грубо говоря, в 10-100 раз "кривее".
Как Вариант используйте операцию "Аналитическое вычитание" (http://forum.razved.info/index.php?t=950&&st=0) и избавьтесь от Алексея Николаевича, Алексея Константиновича, Татьяны, ... тележурналиста и других, всплывающих во время поиска.
А ещё лучше, составьте тщательнее пакет запросов.
А ещё лучше, посмотрите #12. На 100% не помню, но 99%, что фразы прописывать можно.
-- Доктор ТуамОсес написал 19 сентября 2013 10:17
Алексей Мыльников написал:
Ещё раз коротко: во-первых, уже есть возможность рубрикации сниппетов
Нету. В триальной версии нету.

Алексей Мыльников написал:
сложные правила на сниппете, составляющем 0.1-0.01 часть контента ссылки сработают, грубо говоря, в 10-100 раз "кривее".
Ну чтобы юзать регэкспы не на сниппете, а на всем тексте веб-страницы её нужно сначала скачать. Вы предлагаете людям скачивать все 800 ссылок объединения выдачи?
Ведь куда как лучше отфильтровать не нужные 90% ссылок для которых можно понять что они не содержат нужной информации даже по маленькому сниппету, а уж оставшиеся страницы полностью скачивать.
====================================

Судя по ЭТОМУ нет (http://forum.razved.info/index.php?t=1007&p=45833#pp45833)
==========================
Алексей Мыльников написал:
Как Вариант используйте операцию "Аналитическое вычитание" и избавьтесь от Алексея Николаевича, Алексея Константиновича, Татьяны, ... тележурналиста и других, всплывающих во время поиска.
Не очень понял.
Вы предлагаете сначала создать запрос в котором будет "Алексей Толстой"
Потому запрос: "Алексей" "Толстой"
А потом из второго запроса вычесть первый?
Я правильно понял Вашу мысль?
=========================
Алексей Мыльников написал:
На 100% не помню, но 99%, что фразы прописывать можно.
Ещё раз попробовал разные варианты и наконец понял в чём дело. Почему у меня фразы не фильтровались. Потому что слово "Алексей" в выдаче было написано жирным шрифтом, а "Толстой" - обычным. Т.е. если глянуть в исходный код сниппета то видно , что слова разделены между собой не только пробелом, но и тегами. Но я то не знал, что в Вашей программе поиск фраз из черного списка "сырой"/"в лоб" (т.е. ведется по исходному коду страницы включая символы тегов (\ < > и др.). А Вы это нигде не написали.
Т.е. когда я написал <b>Владимир</b> Ильич, то у меня из объединения выдач исчезли сниппеты, содержащие фразу "Владимир Ильич"

Алексей Мыльников написал:
На 100% не помню
Вот для этого и нужно писать нормальный хэлп, где всё чётко и ясно было бы прописано. Чтобы юзверям не приходилось работать с программой по методу "научного тыка". Ведь зачастую юзвери отказываются юзать мощные классные программы только потому что нет нормального хэлпа к ним. Потому что получается, что программа вроде как хорошая, но "вещь в себе".
Или юзвери юзают только 10% возможностей программы (потому что про другие либо ничего не знают, либо не понимают как их использовать, потому что хэлпа нормального нет) и бывают разочарованы. И переходят на др. программу
-- Семёныч написал 20 сентября 2013 10:15
Впечатляет меня упорство человека, юзающего кастрированную версию программы (дэмо-версию) и при этом, умудряющийся в ней разобраться и что-то из неё выжать.
 Ну, это сухие эмоции.
Ну, это сухие эмоции.По-делу, соглашусь с Доктор ТуамОсес в том, что хэлп к программе не поспевает за теми функциями, которые в ней постоянно появляются. Последний раз мануал редактировали год назад? А изменений в ней добавилось и немало! Сомневаюсь, что в хэлпе можно прописать все нюансы программы, но стремиться к этому надо. А если кто-то из пользователей нашёл некий нюанс, не включённый в хэлп, то почему бы этот нюанс туда не добавить?
-- Алексей Мыльников написал 20 сентября 2013 11:10
Уважаемый Доктор ТуамОсес, Блэклист сайтов создавался для:
petryashov написал:
Алексей, мы когда-то этот вопрос уже обсуждали, но он как-то завис.Оно и понятно: практически в каждом сниппете есть URL.
Суть:в тех случаях, когда мы ежедневно мониторим группу запросов в СайтСпутнике, достаточно быстро выявляется группа сайтов, которые не имеют отношения к теме, но не отфильтровываются даже самыми изощренными запросами в поисковых системах.
Можно ли создать некий Блеклист, в который пользователь может включать сайты, которые СайтСпутнику посещать не надо?
Попутно этот приём можно применить и для фильтрации сниппетов по контексту, а именно: по единичным словам, без учета регистра. Развивать этот прием (уже в третий раз пишу) не считаю нужным, потому что в SiteSputnik News это уже есть (оно получилось "попутно", без целенаправленной разработки) и потому что применение языка запросов к сниппетам приводит к потере значимой информации. Я не сторонник доведение какой-то идеи до абсурда.
По поводу Help(a). Отставание его содержания от производимого матобеспечения есть, но на форуме я всегда декларирую новые функциональные возможности программы, также выкладываю их на странице _http://sitesputnik.ru/Public.htm и в колонке "Хроника событий" на главной странице сайта о программе СайтСпутник.
-- Доктор ТуамОсес написал 20 сентября 2013 12:15
Алексей Мыльников написал:
применение языка запросов к сниппетам приводит к потере значимой информации
Я же писал:
Доктор ТуамОсес написал:
Ну чтобы юзать регэкспы {прим.ну или как Вы пишите "язык запросов"} не на сниппете, а на всем тексте веб-страницы её нужно сначала скачать. Вы предлагаете людям скачивать все 800 ссылок объединения выдачи?
На этот вопрос ответите?
Разве не эффективней сразу отфильтровать 90% сайтов ещё на этапе анализа содержимого сниппетов, чем тянуть из инета к себе на хард диск ГИГАБАЙТЫ мусора?
Ведь в большинстве случаев уже по сниппету веб-страницы в яндексе можно понять, что полностью читать веб-страницу не стоит. Не согласны?
-- Доктор ТуамОсес написал 20 сентября 2013 12:30
Семёныч написал:
Впечатляет меня упорство человека, юзающего кастрированную версию программы (дэмо-версию) и при этом, умудряющийся в ней разобраться и что-то из неё выжать.
Дело в том, что я привык что триальная версия - это та же Pro версия, но только с искусственно введенными ограничениями (грубо говоря константы в ней просто меньшего значения типа не for i=1 to 1000, а for i=1 to 10 и т.п.). И я привык, что триал версия - это "лицо продукта".
А если триал версия глючит (копки исчезают, постоянно вылетает с потерей данных, описалова нормального нет и т.д. и т.п.) тот какой <пип пип пип> будет покупать Pro-версию?

Т.е., грубо говоря, алгоритм такой:
- Человек пробует триал-версию.
- Она ему нравиться и он хочет большего.
- Он покупает Pro-версию.
А не такой:
- Человек пробует триал-версию.
- Она вызывает у него раздражение своей "сыростью" и глюками.
- Он покупает Pro-версию в надежде "а может там лучше?".
====================================================================================
P.S.Я за свою жизнь юзал для разных целей более 1000 программ. Чтобы их все купить - нужно быть Абрамовичем

А при моей зарплате 20 000 руб в месяц и наличии 4 "спиногрызов" сами понимаете выделить даже 200 руб в месяц на покупку софта - это серьёзный удар по семейному бюджету. Поэтому давайте оставим в покое вопрос "а че он не хочет купить Pro версию и юзает кастрированный триал".
Впрочем я бы не пожалел и 5000 руб даже при моём более чем скромном бюджете если бы функционал программы этого стоил. Но пока я не вижу в программе чего-то такого/эдакого, чтобы я бы аж ахнул. Пока функционал программы такой, что я сам смогу наваять подобный функционал за пару недель на каком-нибудь Autohotkey, Selenium и т.п. Продолжение этой темы ТУТ (http://forum.razved.info/index.php?t=4256)
-- Игорь Нежданов написал 20 сентября 2013 16:57
Доктор ТуамОсес написал:
Доктор ТуамОсес написал:
Ну чтобы юзать регэкспы {прим.ну или как Вы пишите "язык запросов"} не на сниппете, а на всем тексте веб-страницы её нужно сначала скачать. Вы предлагаете людям скачивать все 800 ссылок объединения выдачи?
На этот вопрос ответите?
У меня СайтСпутник работает ежедневно. В среднем вытаскивает каждые сутки от 12 до 18 тысяч полнотекстовых сообщений (а не только ссылок), которые затем вычищаются и рубрицируются в 120 Рубрик. И что? 800 ссылок это "мелочь" для программы.
-- Доктор ТуамОсес написал 21 сентября 2013 2:10
Игорь Нежданов написал:
У меня СайтСпутник работает ежедневно. В среднем вытаскивает каждые сутки от 12 до 18 тысяч полнотекстовых сообщений
Очень любопытно
В связи с этим у меня к Вам ряд вопросов:
- Это в гигабайтах сколько?
- У Вас наверное очень жирный канал (сколько мегабайт в секунду средняя скорость даунлодадинга)
- Зачем Вам так много инфы? Что Вы с ней делаете-то? Или Вы просто сканируете в инет на предмет чего-то конкретного? Типа "а не появилось ли "оно"?"
- Вы согласны, что 99,9 % скаченной инфы - это шлак/мусор? Тогда зачем её качать?
Игорь Нежданов написал:
800 ссылок это "мелочь" для программы.
Но для моего старенького компа и "тоненького" инет канала это огромная нагрузка. 18 000 веб страниц ... это примерно 5 гигабайт инфы в день.
Зачем столько? Ведь человек даже сотню страниц в день не осилит вдумчиво прочитать. Или Вы не читаете, а просто сканируете?
Игорь Нежданов написал:
800 ссылок это "мелочь" для программы.
У меня одна страница загружается в среднем за 20 секунд. 800 x 20 = 16 000 секунд. Т.е. примерно 4,5 часа потребутся программе..
Я за это время 10 раз уже успею вручную "нагуглить" то, что мне надо

Путем анализа выдачи поисковиков и модификации по результатам этой выдачи своих поисковых запросов
И вообще, ИМХО, устраивать у себя на компе мини-гугль (закачивая на хард с целью анализа десятки тысяч ссылок) - это порочная идея.
ИМХО, нужно бить интеллектуальностью, чтобы как можно меньше качать на хард не нужной инфы. А не тупо, "в лоб" качать всё что попалось
За счёт чего это можно сделать?
1) За счёт более детального анализа сниппетов выдачи поисковиков и содержимого все-таки скачанных на хард веб-страниц
2) За счёт более лучших и качественных запросов
Поэтому, ИМХО, главными задачами программы должны быть:
1) автоматизация анализа сниппетов и скачанных веб-страниц
2) автоматизация фильтрации "левой" информации
3) автоматическое (или интерактивное в режиме "подсказка") генерирование новых "хороших" запросов по результатам анализа
-- Игорь Нежданов написал 21 сентября 2013 9:00
Доктор ТуамОсес написал:
В связи с этим у меня к Вам ряд вопросов:
- Это в гигабайтах сколько?
По разному - от двухстрочных сообщений в твиттере или в соцсети, до аналитических текстов в десяток страниц. Поэтому каждый раз по разному.
Доктор ТуамОсес написал:
- У Вас наверное очень жирный канал (сколько мегабайт в секунду средняя скорость даунлодадинга)
Канал не плохой - утверждают, что не менее 512 мегабит.
Доктор ТуамОсес написал:
- Зачем Вам так много инфы? Что Вы с ней делаете-то? Или Вы просто сканируете в инет на предмет чего-то конкретного? Типа "а не появилось ли "оно"?"
У меня за 30 постоянных потребителей информации, каждого из которых интересует от одного до 15 тем (направлений). По этим темам основной вопрос именно тот - "не появилось ли чего то ценного по ней".
Доктор ТуамОсес написал:
- Вы согласны, что 99,9 % скаченной инфы - это шлак/мусор? Тогда зачем её качать?
Нет - это как настроить первичный сбор информации. Т.е выбрать правильные источники, составить правильные запросы и т.п. "мусорной информации" (по ощущениям - не считал) не более 20%. И, полагаю можно еще подсократить, но это нужно тщательнее поработать с источниками.
Доктор ТуамОсес написал:
Зачем столько? Ведь человек даже сотню страниц в день не осилит вдумчиво прочитать. Или Вы не читаете, а просто сканируете?
Надеюсь уже ответил на этот вопрос. Из всего объема именно для меня всего 5 тем, в каждой по 2 - 10 сообщений в сутки.
Медленный инет это не приятно. Но и в этом случае СайтСпутник сильно облегчает жизнь Предполагаю, что вы не используете возможности тонкой настройки (их нет в бесплатной версии) и правильного построения запросов к источникам информации.
Тем ни менее с вашим общим посылом я согласен - на счет того, что нужно максимально поднимать эффективность.
-- Алексей Мыльников написал 22 сентября 2013 19:32
Доктор ТуамОсес написал:
Я же писал:
Доктор ТуамОсес написал:
Ну чтобы юзать регэкспы {прим.ну или как Вы пишите "язык запросов"} не на сниппете, а на всем тексте веб-страницы её нужно сначала скачать. Вы предлагаете людям скачивать все 800 ссылок объединения выдачи?
На этот вопрос ответите?
Разве не эффективней сразу отфильтровать 90% сайтов ещё на этапе анализа содержимого сниппетов, чем тянуть из инета к себе на хард диск ГИГАБАЙТЫ мусора?
Ведь в большинстве случаев уже по сниппету веб-страницы в яндексе можно понять, что полностью читать веб-страницу не стоит. Не согласны?
Отвечу: напишите в Яндексе: Лев /1 Толстой или Лев /2 Толстой и 800 страниц скачивать не надо будет.
Доктор ТуамОсес написал:
А если триал версия глючит (копки исчезают, постоянно вылетает с потерей данных, описалова нормального нет и т.д. и т.п.
А это уже некорректное заявление. Пробный вариант не глючит, а свернулся до минимума и не дает развернуться, потому что срок его действия кончился. Об этом Пользователю постоянно выводится сообщение: "Программа не зарегистрирована, её функциональные возможности огрничены". Остался поиск на глубину одной страницы для основных поисковиков. Вам об этом не раз писали, и не только я. Вы опять повторяете, то на что ранее получили ответ. Если хотите, то в следующей версии я сделаю так, что программа, у которой истек срок опробации, просто не будет открываться.
Доктор ТуамОсес написал:
Поэтому, ИМХО, главными задачами программы должны быть:
1) автоматизация анализа сниппетов и скачанных веб-страниц
2) автоматизация фильтрации "левой" информации
3) автоматическое (или интерактивное в режиме "подсказка") генерирование новых "хороших" запросов по результатам анализа
-- Доктор ТуамОсес написал 23 сентября 2013 1:04
Алексей Мыльников написал:
А это уже некорректное заявление. Пробный вариант не глючит, а свернулся до минимума и не дает развернуться, потому что срок его действия кончился. Об этом Пользователю постоянно выводится сообщение: "Программа не зарегистрирована, её функциональные возможности огрничены". Остался поиск на глубину одной страницы для основных поисковиков. Вам об этом не раз писали, и не только я. Вы опять повторяете, то на что ранее получили ответ. Если хотите, то в следующей версии я сделаю так, что программа, у которой истек срок опробации, просто не будет открываться.
Пробный период если не ошибаюсь 30 дней?
А у меня "возраст" программы всего 2 дня.
А глюки с исчезанием кнопок и вылетами всё равно есть
Алексей Мыльников написал:
напишите в Яндексе: Лев /1 Толстой или Лев /2 Толстой и 800 страниц скачивать не надо будет.
Если бы... Всё было так просто
Алексей Мыльников написал:
Остался поиск на глубину одной страницы для основных поисковиков.
Ну это легко обходится путем создания своего сценария

-- Алексей Мыльников написал 21 июля 2021 13:44
Черные и Белые списки в рамках Проекта
Доступно, начиная с версии SiteSputnik (https://sitesputnik.ru/) Pro 9.9.4.2 от 21.07.2021.
Всё что написано выше, а именно, Черные и Белые списки, действующие в рамках Запроса, - остаётся в силе.
Если эти списки прописаны, то они приоритетнее нижеследующих списков.
В рамках Проекта Черные и Белые списки можно прописать следующим образом:
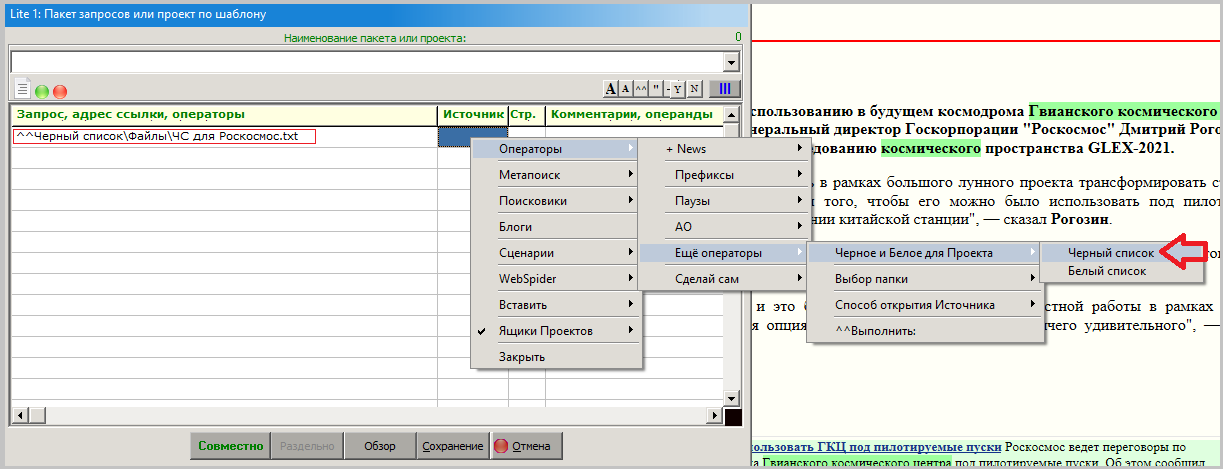 (https://sitesputnik.ru/Help/Pic/F/Sputnik_Black_List.png)
(https://sitesputnik.ru/Help/Pic/F/Sputnik_Black_List.png)Красная стрелка показыает как выбирается текстовый файл, содержащий Черный и/или Белый список, а
Красной линией обведено имя выбранного файла.
Пример содержания файла:
sitesputnik.ru
freesoft.ru
ci-razvedka.ru
razvedka-internet.ru
info-war.ru
nejdanov.ru
informnn.ru
marketinginform.ru
forum.razved.info
Имена сайтов или любые другие лексемы записываются в нём просто в столбик.
Этот форум работает на скрипте Intellect Board
© 2004-2007, 4X_Pro, Объединенный Открытый Проект